
-min.png)
What are AI Evals?
AI evals are automated tests that measure whether your AI does what you need it to do. Think of them like unit tests for traditional software, except instead of checking if a function returns exactly "true" or "false," you're measuring degrees of quality on a scale from 0 to 1.
Braintrust breaks down the "anatomy of an Eval" into three core components:
Task: What you want the AI to do. This can be a single prompt, a chain of prompts, or a full agent.
Dataset: The fixed set of test cases you run the task on, representing real usage.
Scores: How you evaluate the output, using either code-based scores for deterministic checks or LLM-as-a-Judge scores for non-deterministic or subjective checks.
When you run an eval, you feed each example from your dataset into your task, then score the output. Run this across all your test examples and you get an aggregate score that tells you exactly how well your AI performs.
-min.png)
An example: Hubo's digital brochure creator
To see how this works in practice, let's walk through one of the evals we wrote for the digital brochure creator for Hubo.
Task: Take a brochure page, detect all products on it and match them with the correct products in Hubo's web catalog.
Dataset: Actual brochure pages. Some with a few products neatly arranged, others with many products crammed together, some with products at angles, some with overlapping text.
Scores: We scored whether all products on the page were detected and whether each detected product was matched to the correct item in the web catalog. A score of 1.0 means every product was found and matched correctly, while a score of 0.6 means some products were missed or matched incorrectly.
Running these evals showed us where the system struggled and confirmed that improvements for complex layouts did not negatively affect simpler ones. Every change was measurable.
Three challenges Evals solve
Which AI model should we use?
Different models excel at different tasks. Instead of relying on intuition or benchmarks, you can run your dataset across multiple models and compare scores to see which one actually performs best for your use case. When a new model launches, you can evaluate it immediately and decide whether switching makes sense.
Can we get the same results for less?
The best-performing model is not always the most cost-effective one. Evals let you compare cheaper models against your quality bar and make informed trade-offs, for example choosing a model that delivers 95% of the quality at a fraction of the cost.
How do we know when something breaks?
Without evals, regressions often surface only after users notice. With evals, you can catch quality drops as soon as you change a prompt, model, or agent, allowing you to fix issues before they reach production and ship faster with confidence.
Build the feedback loop
Evals are not a one-off measurement. They create a feedback loop: measure performance, make a change, measure again. Each iteration tells you what improved, what regressed, and where to focus next.
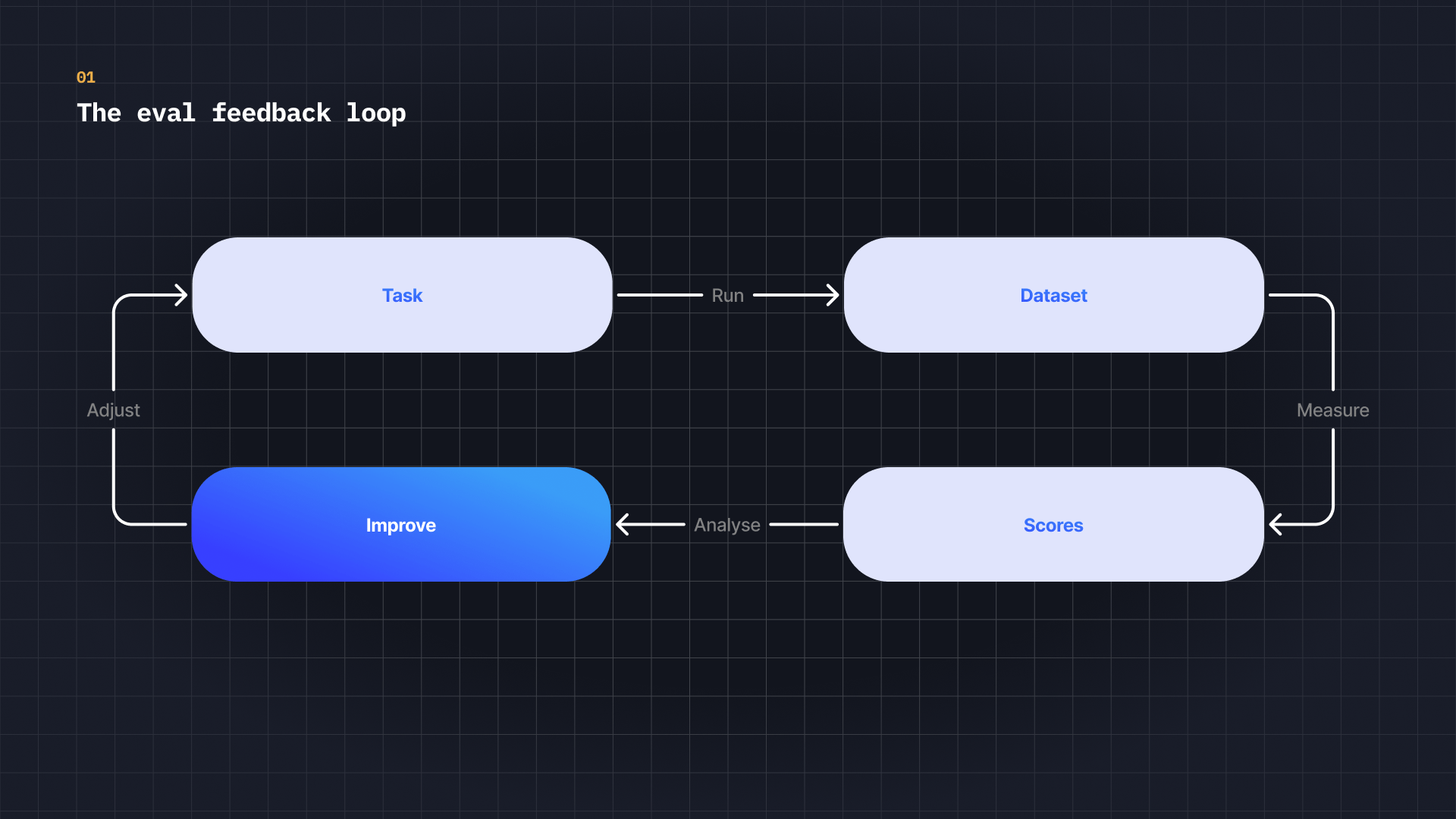
Without this loop, you are guessing. Changes go to production and you hope they help. With evals, quality becomes visible before users ever notice an issue, making it possible to ship changes faster and with confidence.
You do not need a perfect setup to start. Pick a handful of real examples, define a single score, and run your first eval. That is the start of a feedback loop that turns uncertainty into something you can measure and act on.



